高 QPS 下自研 Rpc 框架性能调优
问题背景
公司是基于医疗互联网的 Saas 模式,给几千家医院提供互联网医院服务。突然 5.23 浙江省中乌梅汤 2.0 爆红全网。
排查回顾
现象
高峰时期,用户进入公众号首页出现白屏,并弹出“系统繁忙”。
救火
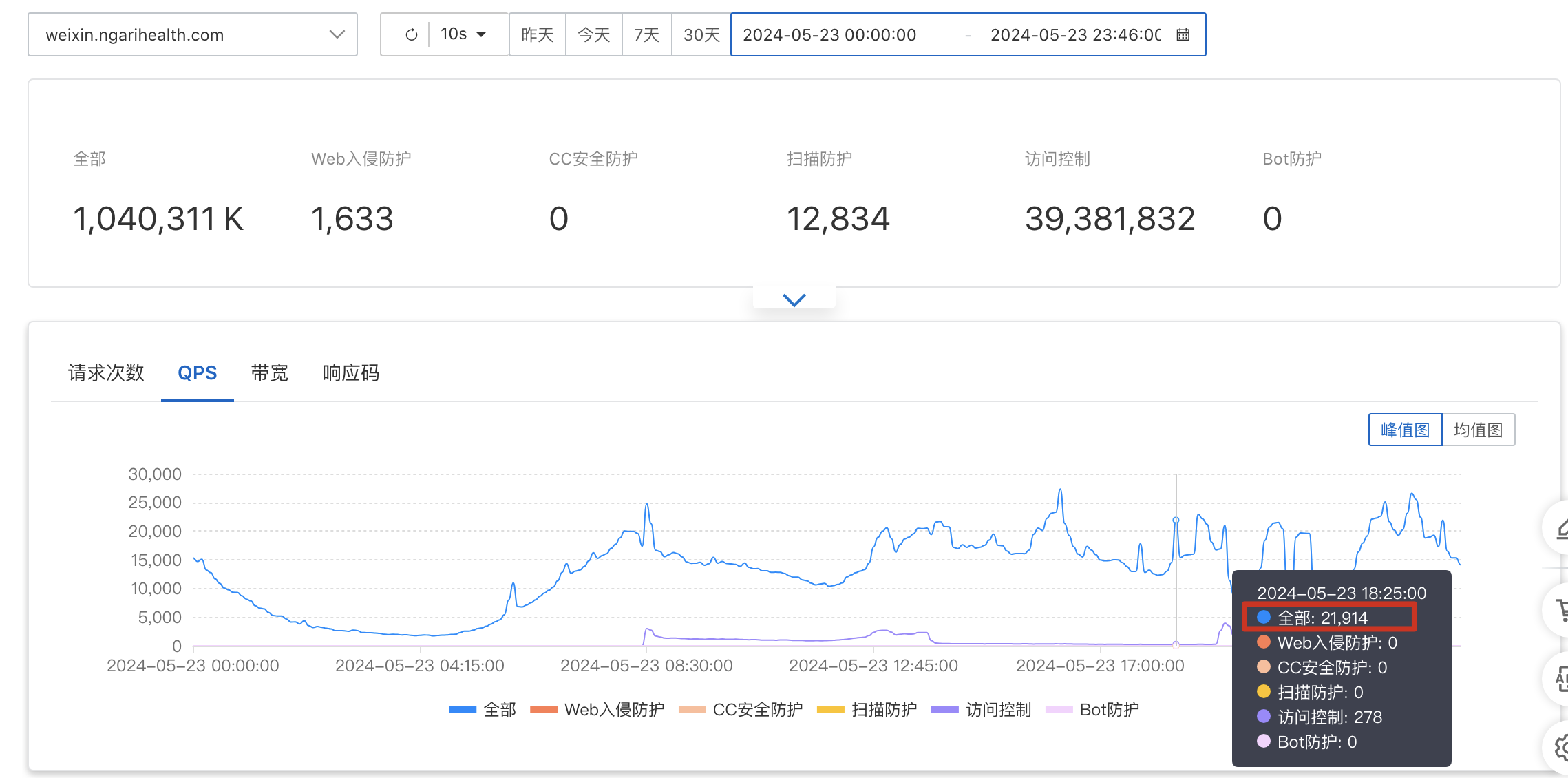
查看阿里云 waf 域名 QPS 达到 15000/s,在网关服务开启了限流、调整 Tomcat 线程数至 2000 并紧急增加了机器。
治理
后续发现流量在持续上涨,对便捷购药功能链路上的流量进行打标,对服务部署省中集群,防止对其他医院产生影响。
排查
在后续放量的过程中发现,当 waf qps 达到 19000/s 时,底层的账户(account)服务和公共基础服务(basic)的耗时会出现陡增,并出现大量超时的情况。

阿里云 waf 域名流量监控
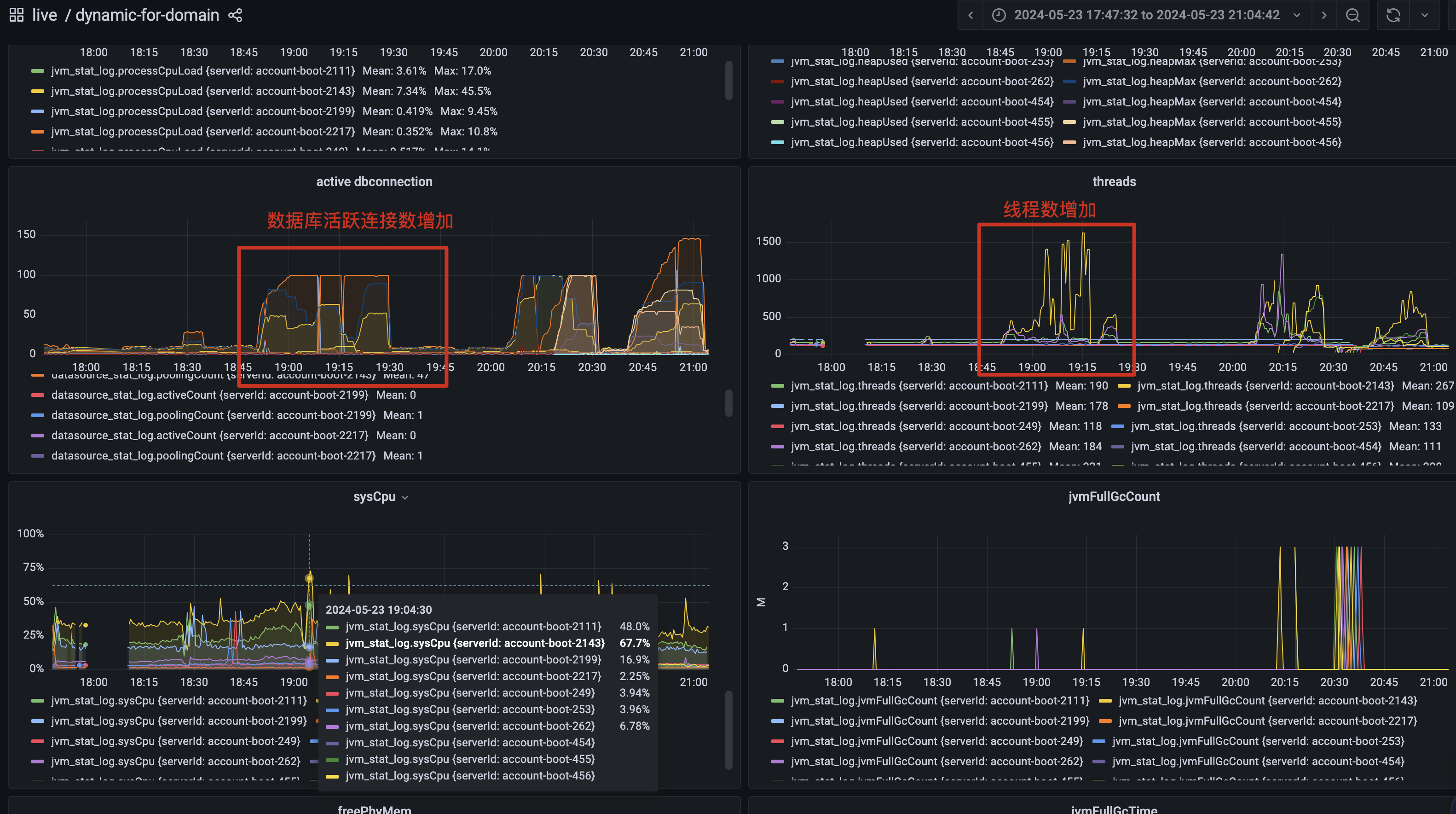
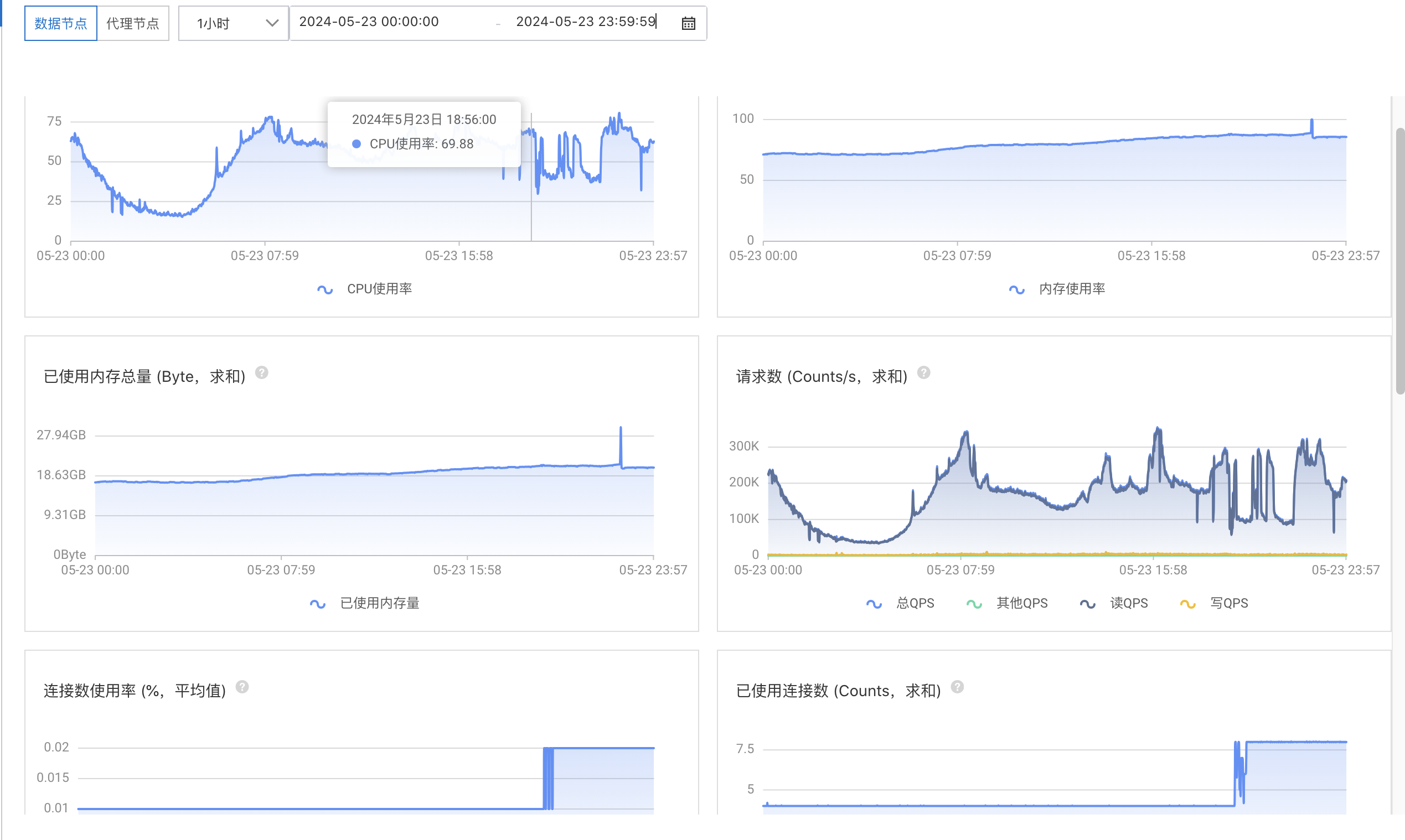
排查服务监控发现服务 CPU 和系统 CPU 没有打满的情况,但是数据库连接数和线程数有明细的波动
account 服务监控
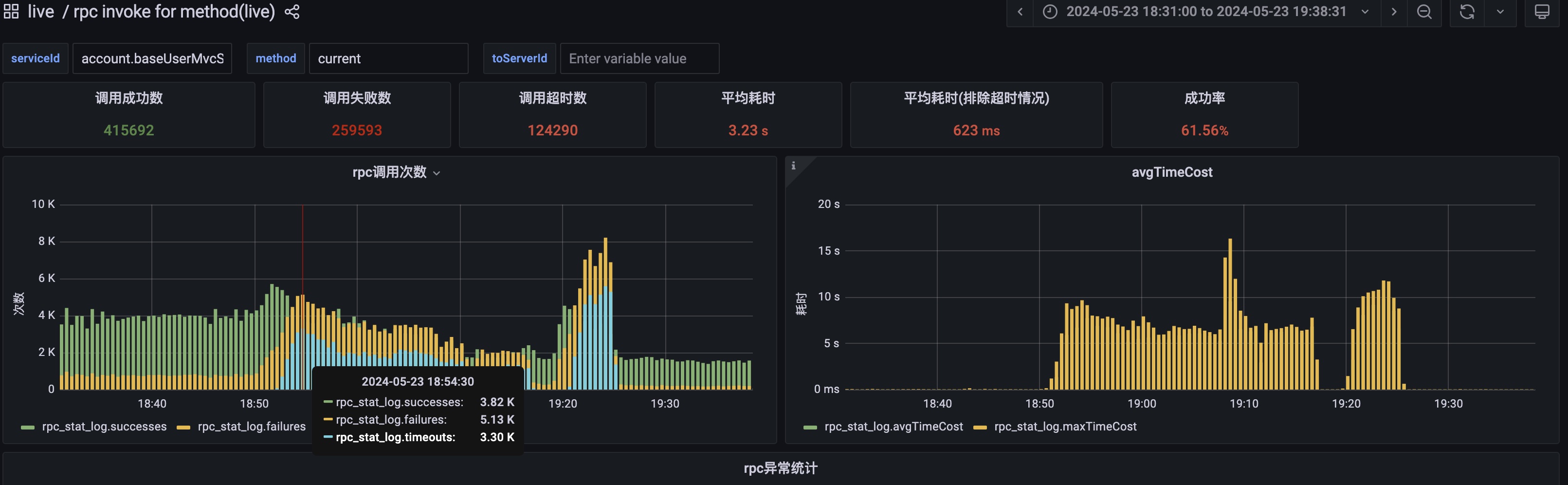
排查 account 服务底层获取当前用户接口,此时 account.current 接口 rpc 调用次数翻了 3 倍,单机 QPS 仅 300/s。耗时由 20ms 增加到了 7000ms 甚至到 15000ms
account.current rpc 接口监控
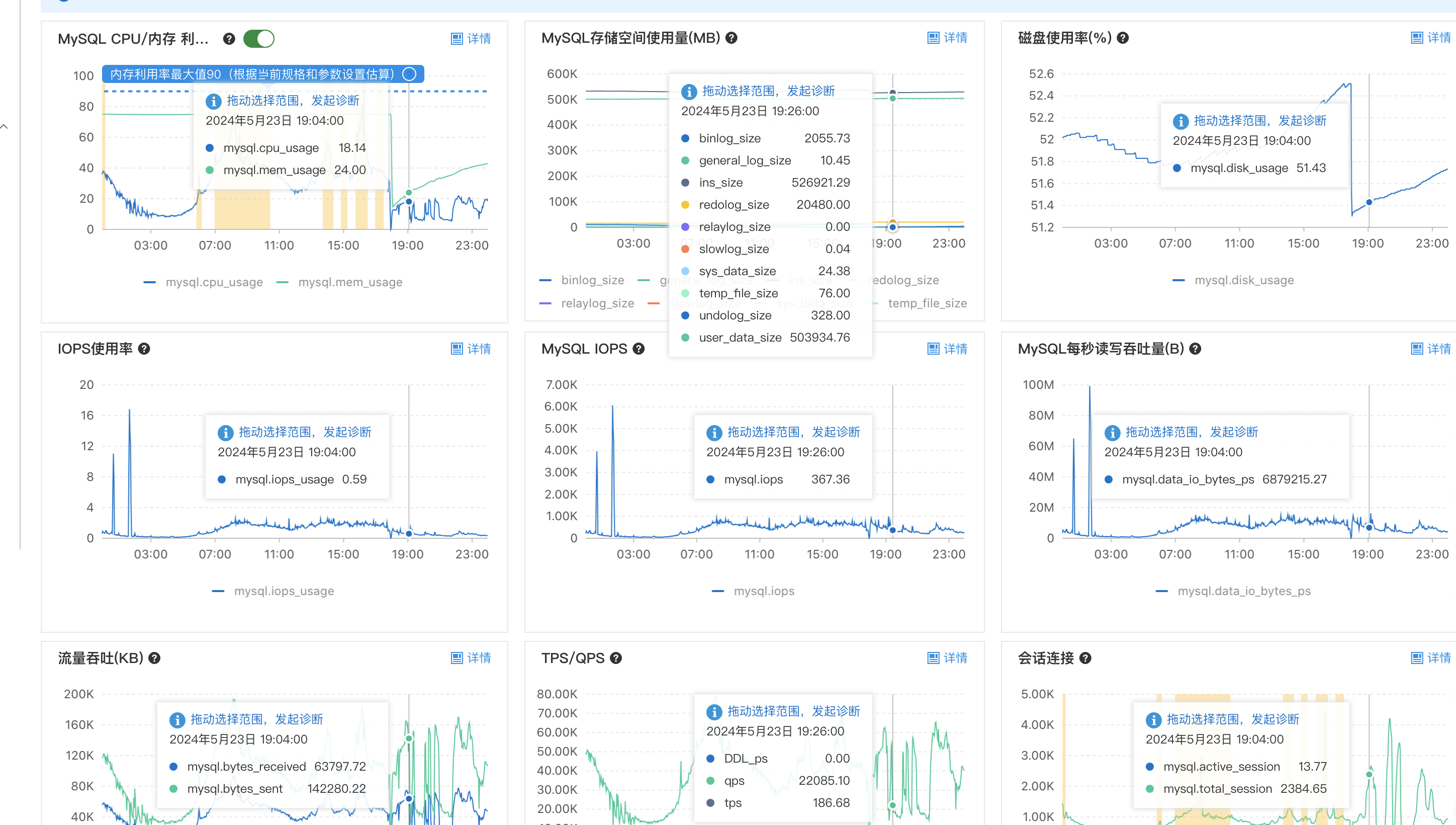
第一反应是数据库影响了,排查阿里云 RDS 监控
阿里云 RDS 监控
CPU 有波动但是没有打满,慢查诊断正常,基本排除是数据库影响。
走查 current 接口的代码,发现有 redis 连接操作,读取数据库操作,本地缓存操作。
排查 redis 监控
阿里云 redis 监控
CPU,连接数,大 key 诊断并无明显异常。
- 发现 account 服务省中集群机器数量只有 3 台,尝试增加三台机器,并没有效果;
- 对 current 接口进行压测,并不能复现线上的情况,排查陷入了僵局
因为线上的情况比测试环境要复杂,经过团队讨论,决定进行仿真情况进行链路压测。
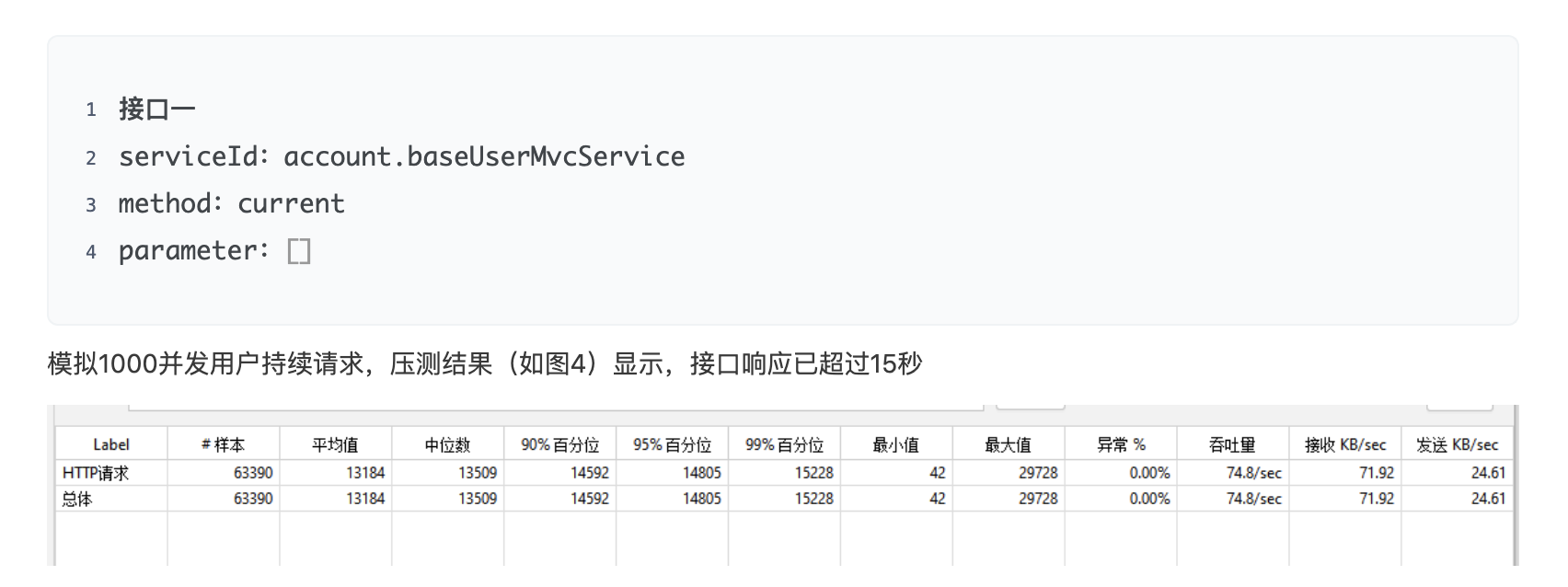
在运维的帮助下,我们部署了 weixin 网关服务,account 账户服务,basic 基础服务,对 account.current 进行了压测,成功复现。
account 并发 1000 下的压测结果
在之前的排查结果下,我们将目标聚焦下网关服务身上,进行了一下尝试
- 调整 tomcat 线程数将 2000 的 tomcat 线程数调整至 500,发现平均耗时减半
- 调整系统 TCP 参数
wmen、rmen、tcpmen,文件句柄参数fs.file-nr、fs.file-max发现并无效果
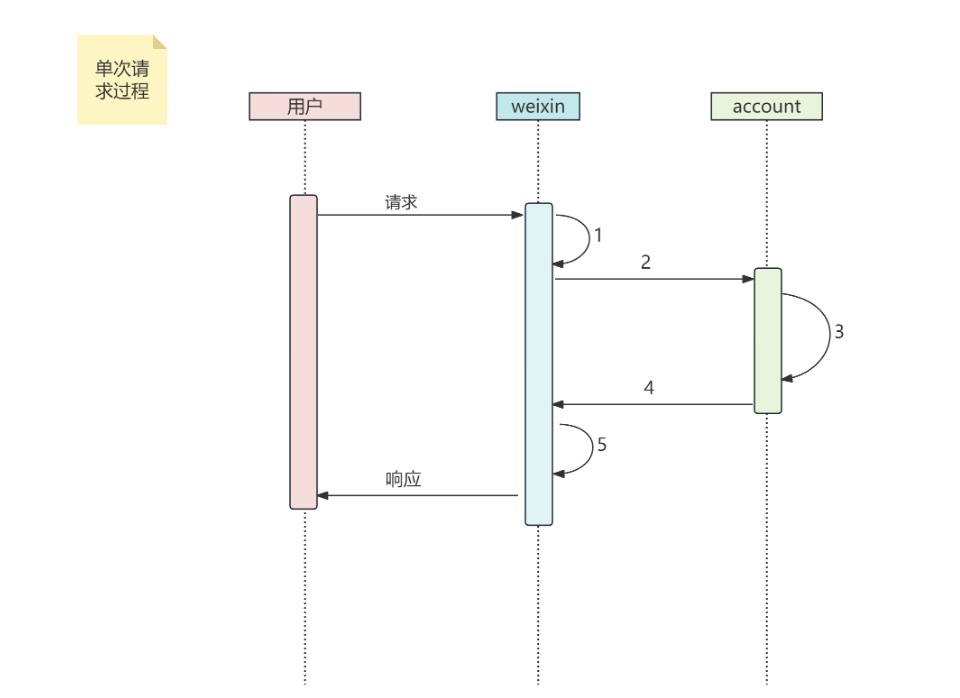
梳理请求链路
account#current 方法时序图
使用 arthas 抓取压测链路上的耗时,发现服务主要耗时在第 4 步,account 服务返回结果时候异常。排查了自研的 RPC 框架,无法确定此时的卡点是 netty 的在 client 还是 server 端。
自研 RPC 框架
走查代码,进行了框架层面的测试发现有脱敏 filter,去除后发现耗时从 15s 下降到 2 秒,看到了希望。我们尝试用 arthas 抓取脱敏方法的耗时只有 100ms 这和我们的期望有所偏差。
排查服务线程情况,发现 account 有 netty 的一个 NioEventLoop 线程经常被阻塞,而其他的 NioEventLoop 线程却是空闲状态。怀疑是这个线程导致了耗时,尝试调整 WorkGroop 线程数,发现并没有效果。
通过对接口的深入分析,发现业务中对脱敏 filter 会执行多次操作,一次脱敏 5ms 左右更关键的信息是执行脱敏的接口是 BoosGrop 线程,此线程会跟请求端绑定,在 IP 不变的情况下次线程固定不变,在高并发的情况下后续的线程就会阻塞。
终章
我们将脱敏的执行线程调整至 WorkGroup,见证奇迹!
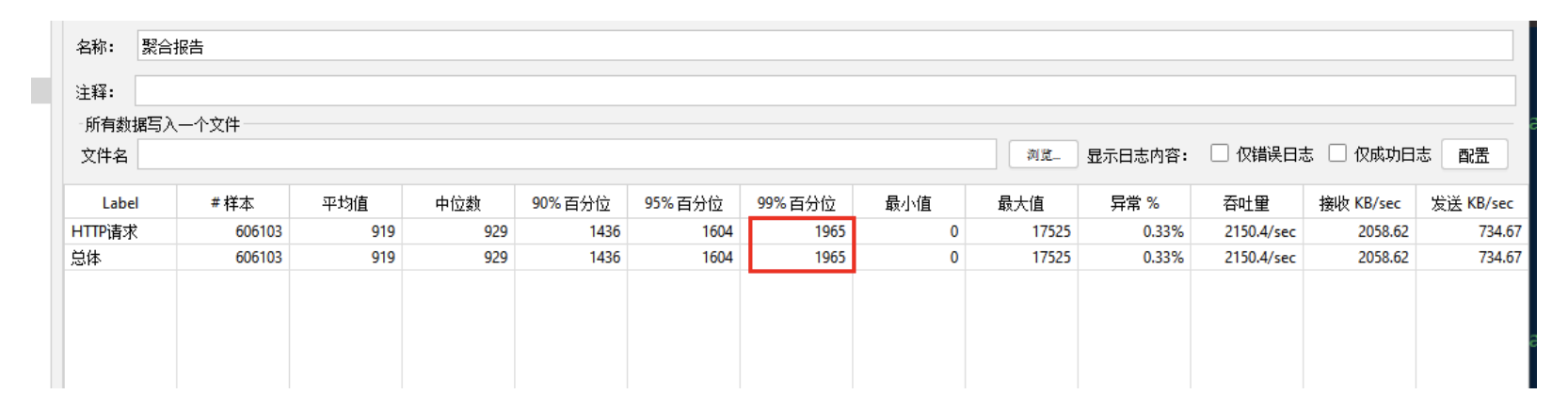
在 2000 并发的情况下进行接口压测,99%的请求可以在 2s 内返回,根据单接口的耗时预估,这些请求主要是积压在 weixin 网关服务,符合预期。
回顾与反思
由于是突发的大流量的情况,且线上情况复杂,对排查造成了一些误导导致排查陷入了僵局。还是需要步步为营,梳理排查手册,增加大流量应急预案。
对于底层框架层的代码必须做好细致入微的考量,且进行严格的压测,包括链路压测。才可以推送给业务部门,埋下的隐患在时机成熟的时候将带来致命的打击