Kubernetes 浅入浅出
引言
Kubernetes 是做什么的?什么是 Docker?什么是容器编排?Kubernetes 是如何工作和扩展的?
简介
Kubernetes 这个名字源于希腊语,意为“舵手”或“飞行员”
Kubernetes 是一个自动化部署、扩容和管理容器应用的开源系统。是 Google 基于其内部容器调度平台 Borg 的经验开发的。2014 年开源,并作为 CNCF(云原生计算基金会)的核心发起项目。
容器变迁
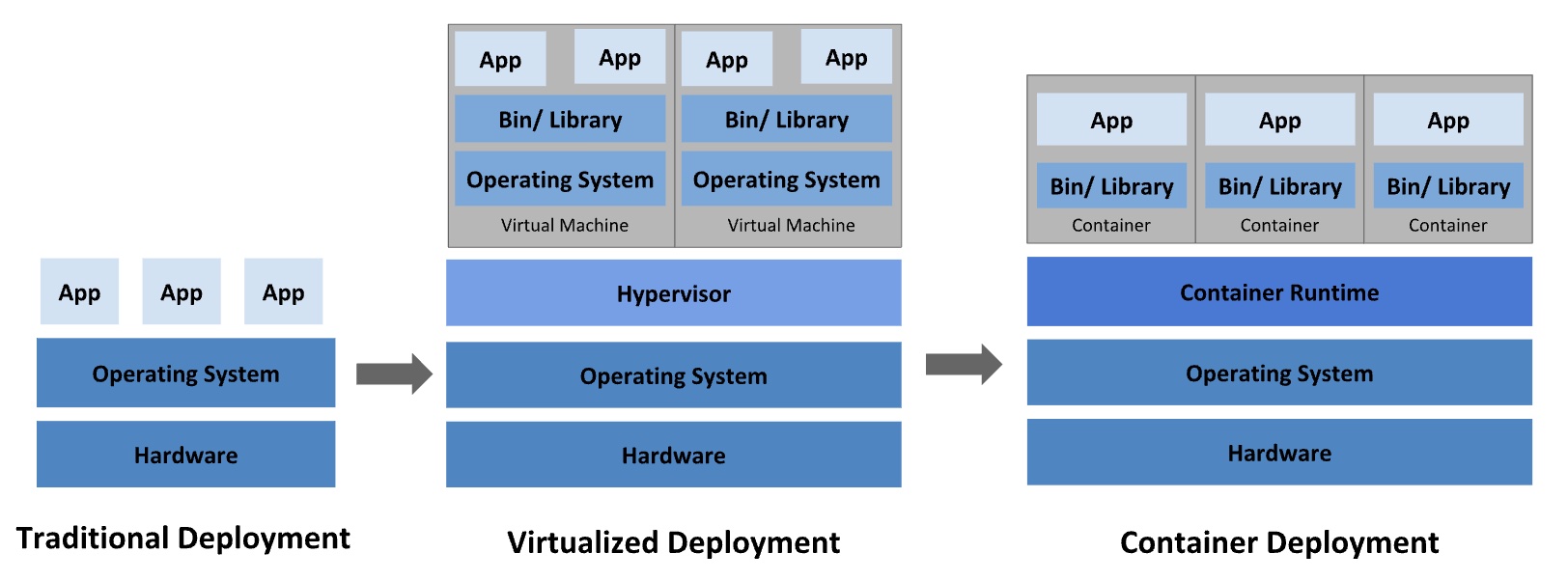
传统时期
- 在物理服务器上运行应用程序。 由于无法限制在物理服务器中运行的应用程序资源使用,因此会导致资源分配问题。
虚拟化部署
假如你要在虚拟机上运行一个网络应用——包括一个 MySQL 数据库、一个 Vue 前端和一些 Java 库,在 Ubuntu 操作系统 (OS) 上运行。将应用程序打包成一个虚拟机镜像,这个镜像中包括了 Ubuntu 操作系统。这使得虚拟机变得非常笨重——通常有几个 G 的大小。
- 虚拟化技术被引入了。虚拟化技术允许你在单个物理服务器的 CPU 上运行多台虚拟机(VM)。 虚拟化能使应用程序在不同 VM 之间被彼此隔离,且能提供一定程度的安全性, 因为一个应用程序的信息不能被另一应用程序随意访问。
- 每个 VM 都具有自己的文件系统、CPU、内存、进程空间等
- 依赖升级困难、性能损耗较大
容器部署
容器是继虚拟机之后更高层次的抽象,在这层抽象中,整个应用程序的每个组件被单独打包成一个个独立的单元,这个单元就是所谓的容器。上面的例子中,Ubuntu 操作系统就是一个单元(容器)。MySQL 数据库是另一个容器,Vue 环境和随之而来的库也是一个容器。
- 容器类似于 VM,但是更宽松的隔离特性,使容器之间可以共享操作系统(OS)
- 类似于船舶或港口中集装箱的堆叠方式,每个容器的稳定性都依赖于下面的容器的支持。
Docker
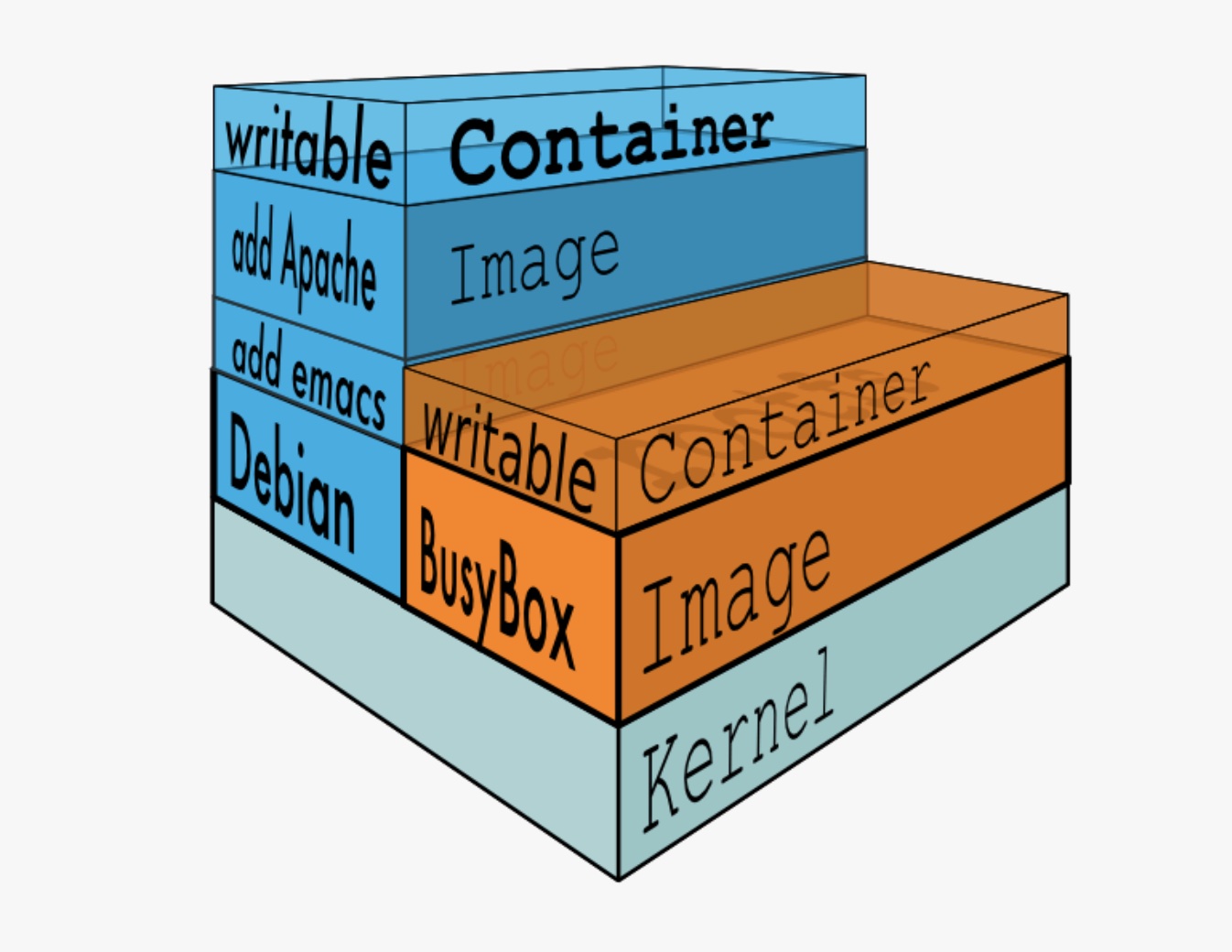
Docker 是一个开源的应用容器引擎,开源于 2013 年,是一种资源虚拟化技术,让开发者可以打包他们的应用以及依赖包到一个可移植的容器中,然后发布到任何流行的 Linux 机器上。
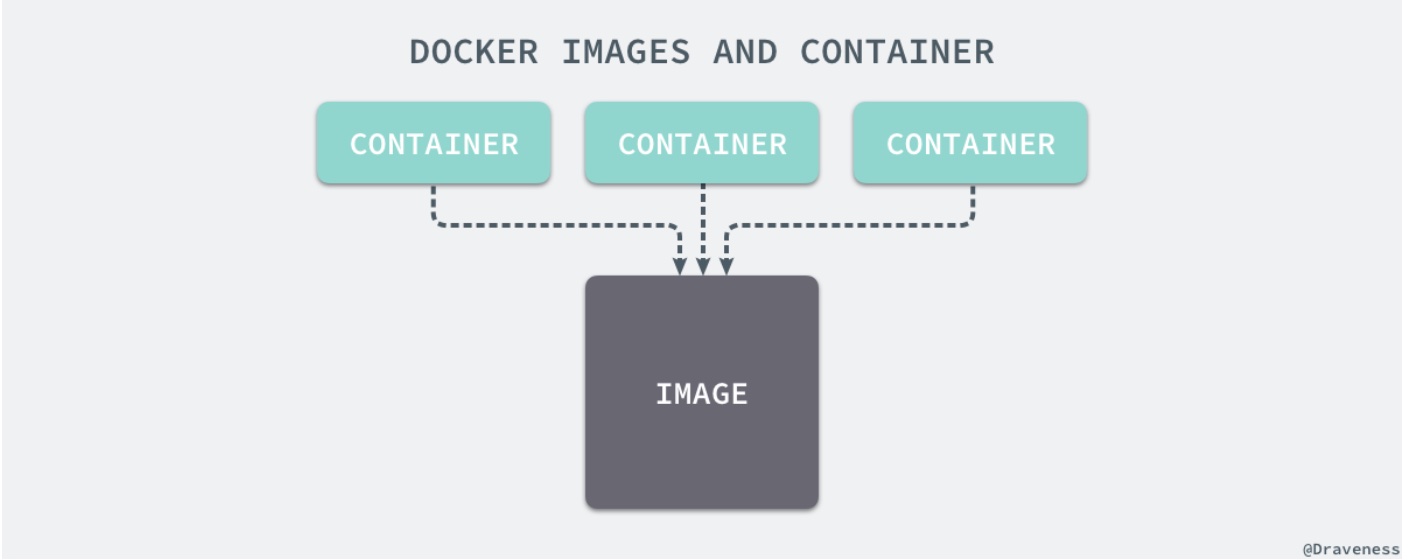
Docker 由镜像、镜像仓库、容器三个部分组成。
Docker 镜像其实本质就是一个压缩包,一个文件。Docker 中的每一个镜像都是由一系列只读的层组成的,Dockerfile 中的每一个命令都会在已有的只读层上创建一个新的层:
1 | FROM ubuntu:15.04 |
容器和镜像的区别
所有的镜像都是只读的,而每一个容器其实等于镜像加上一个可读写的层,也就是同一个镜像可以对应多个容器。每一个镜像层或者容器层都是 `/var/lib/docker/` 目录下的一个子文件夹;
进程:它表示一个正在执行的程序,也是在现代分时系统中的一个任务单元。
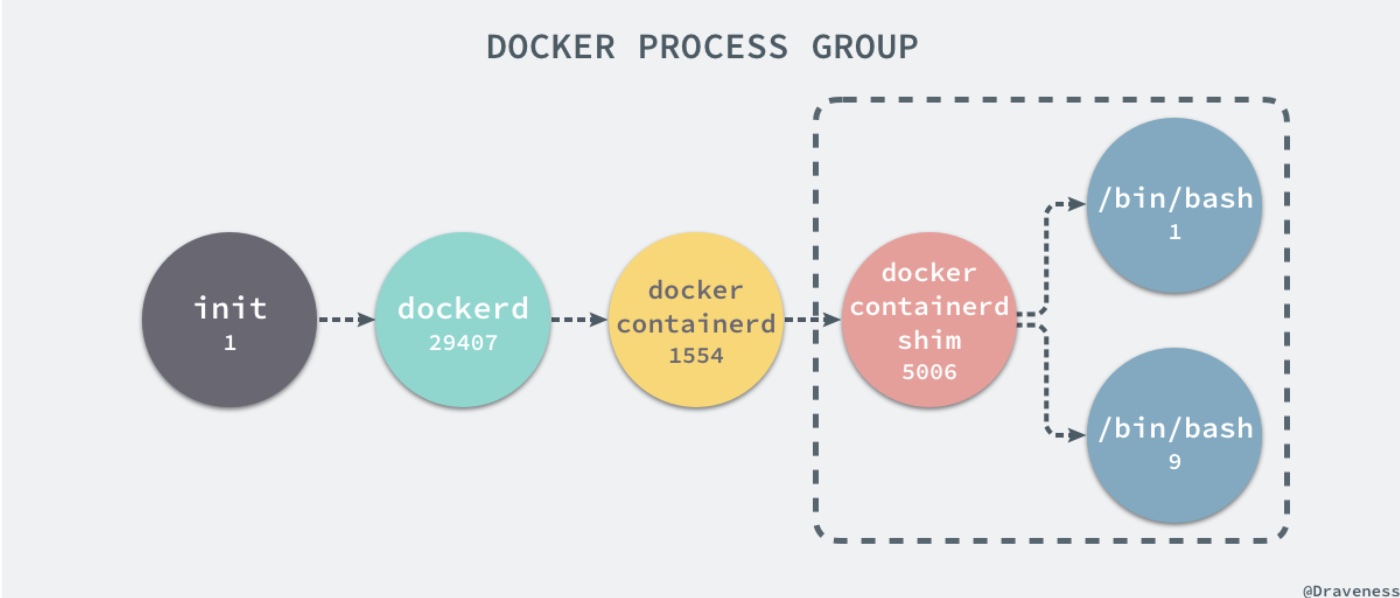
init进程负责内核的一部分初始化工作和系统配置
网络:Host、Container、None 和 Bridge 模式
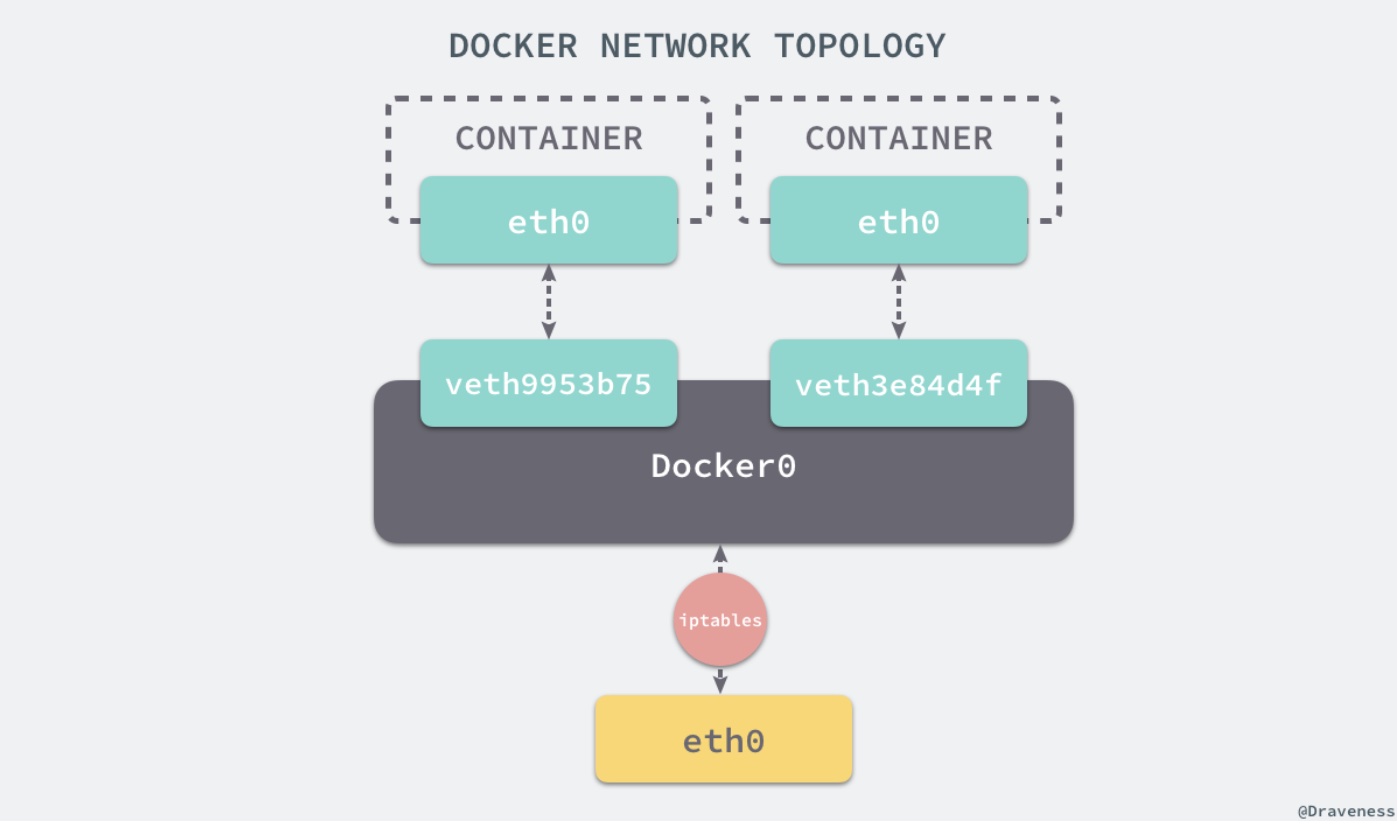
默认Bridge:分配隔离的网络命名空间之外,Docker 还会为所有的容器设置 IP 地址。
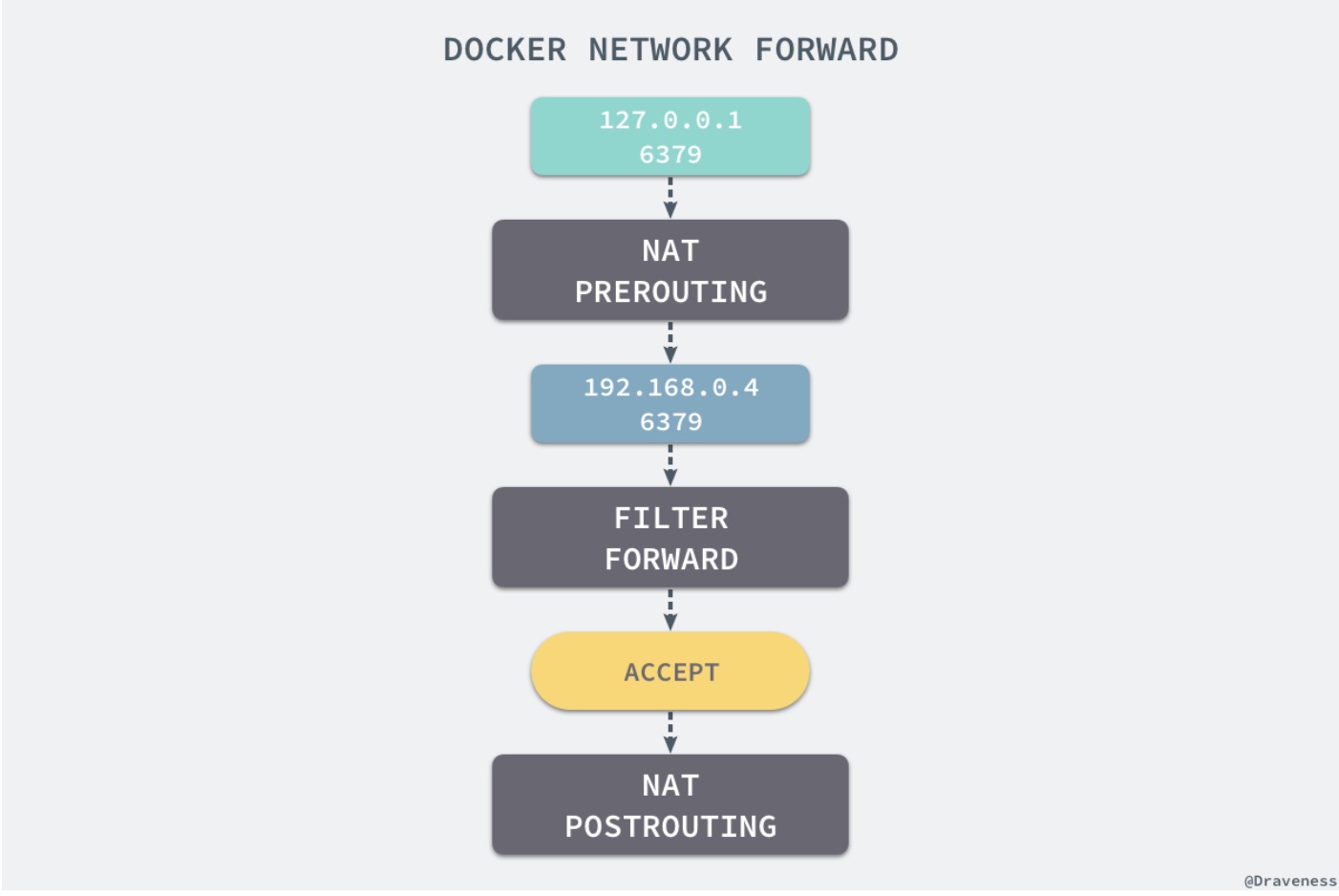
Eth0:虚拟网卡与 Docker0 虚拟网桥相连,网桥 docker0 通过 iptables 中的配置与宿主机器上的网卡相连,所有符合条件的请求都会通过 iptables 转发到 docker0 并由网桥分发给对应的机器。
1 | docker run -d -p 6379:6379 |
挂载点:用于隔离进程间的文件系统,禁止访问宿主机上其他目录.chroot
Docker 这种虚拟化技术的出现有哪些核心技术的支撑。

Namespaces:命名空间 (namespaces) 是 Linux 为我们提供的用于分离进程树、网络接口、挂载点以及进程间通信等资源的方法。Linux 的命名空间机制提供了以下七种不同的命名空间,包括 CLONE_NEWCGROUP、CLONE_NEWIPC、CLONE_NEWNET、CLONE_NEWNS、CLONE_NEWPID、CLONE_NEWUSER 和 CLONE_NEWUTS,通过这七个选项我们能在创建新的进程时设置新进程应该在哪些资源上与宿主机器进行隔离。Docker 通过命名空间成功完成了与宿主机进程和网络的隔离。
CGroup:Control Groups 能够隔离宿主机器上的物理资源,例如 CPU、内存、磁盘 I/O 和网络带宽。
在 CGroup 中,所有的任务就是一个系统的一个进程,而 CGroup 就是一组按照某种标准划分的进程,在 CGroup 这种机制中,所有的资源控制都是以 CGroup 作为单位实现的,每一个进程都可以随时加入一个 CGroup 也可以随时退出一个 CGroup。
UnionFS:UnionFS 其实是一种为 Linux 操作系统设计的用于把多个文件系统『联合』到同一个挂载点的文件系统服务。Docker 支持aufs、devicemapper、overlay2、zfs 和 vfs 等等存储驱动
k8s 名词解释
NameSpace:提供一种机制,将同一集群中的资源划分为相互隔离的组
Node:通过将容器放入在节点(Node)上运行的 Pod 中来执行你的工作负载,可以是物理机、虚拟机。每个节点包含运行 Pod 所需的服务;有 2 种类型的节点——master 节点和 worker 节点,所以说 Kubernetes 是主从结构的;主节点是一个控制其他所有节点的特殊节点,它向集群中的所有其他节点发送消息,将工作分配给它们,工作节点向主节点上的 API Server 汇报。节点上的组件包括 kubelet、 容器运行时以及 kube-proxy。
Pod:资源分配和调度的最小单位,可由多个容器(一般而言一个容器一个进程,不建议一个容器多个进程)组成
Kubernetes 对象:持久化的实体,用实体表示集群的状态,操作 k8s 对象需要用到 kubernetes api,例如 kubectl-命令行接口 CLI。一般会使用.yaml描述。例如:Pod、Service、Volume,Namespace集群中的四大对象
每个对象都包含两个嵌套对象:Spec 和 Status
Spec:表示我们期望的状态
Status:对象的当前状态
Service: service 是一组逻辑上的 pod,它提供了一个单一的 IP 地址和 DNS 名称,你可以通过它访问服务内的所有 pod。在 Kubernetes 中定义了一个服务的访问入口地址,前段的应用(Pod)通过这个入口地址访问其背后的一组由 Pod 副本组成的集群实例,Service 与其后端 Pod 副本集群之间则是通过 Label Selector 来实现无缝对接的。
kubectl:kubectl 是一个命令行工具,用于与 Kubernetes 集群和其中的 pod 通信。
Metadata~~~~:
1 | // 元数据对象定义 |
Annotation: 注解为对象附加任意的非标识的元数据,Map 中的键和值必须是字符串。 换句话说,你不能使用数字、布尔值、列表或其他类型的键或值。
1 | "metadata": { |
Label && 标签选择器:附加到 Kubernetes 对象(比如 Pod)上的键值对,标签可以用来选择对象和查找满足某些条件的对象集合。
1 | # 核心 API 中组 api/v1 |
字段选择器~~~~:允许你根据一个或多个资源字段的值 筛选 Kubernetes 资源
1 | ## namespace |
Volume:Pod 中能够被多个容器访问的共享目录,Volume 与 Pod 的生命周期相同,但与容器的生命周期不相关,当容器终止或者重启时,Volume 中的数据也不会丢失。
ConfigMap:资源对象用于解决服务配置文件修改问题,将配置项 Map 的数据持久化存储在 Kubernetes 的 Etcd 数据库中。将存储在 etcd 中的 ConfigMap 通过 Volume 映射的方式变成目标 Pod 内的配置文件,不管目标 Pod 被调度到哪台服务器上,都会完成自动映射。
设计理念
首先,最重要的是你需要认识到 Kubernetes 利用了“期望状态”原则。就是说,你定义了组件的期望状态,而 Kubernetes 要将它们始终调整到这个状态。
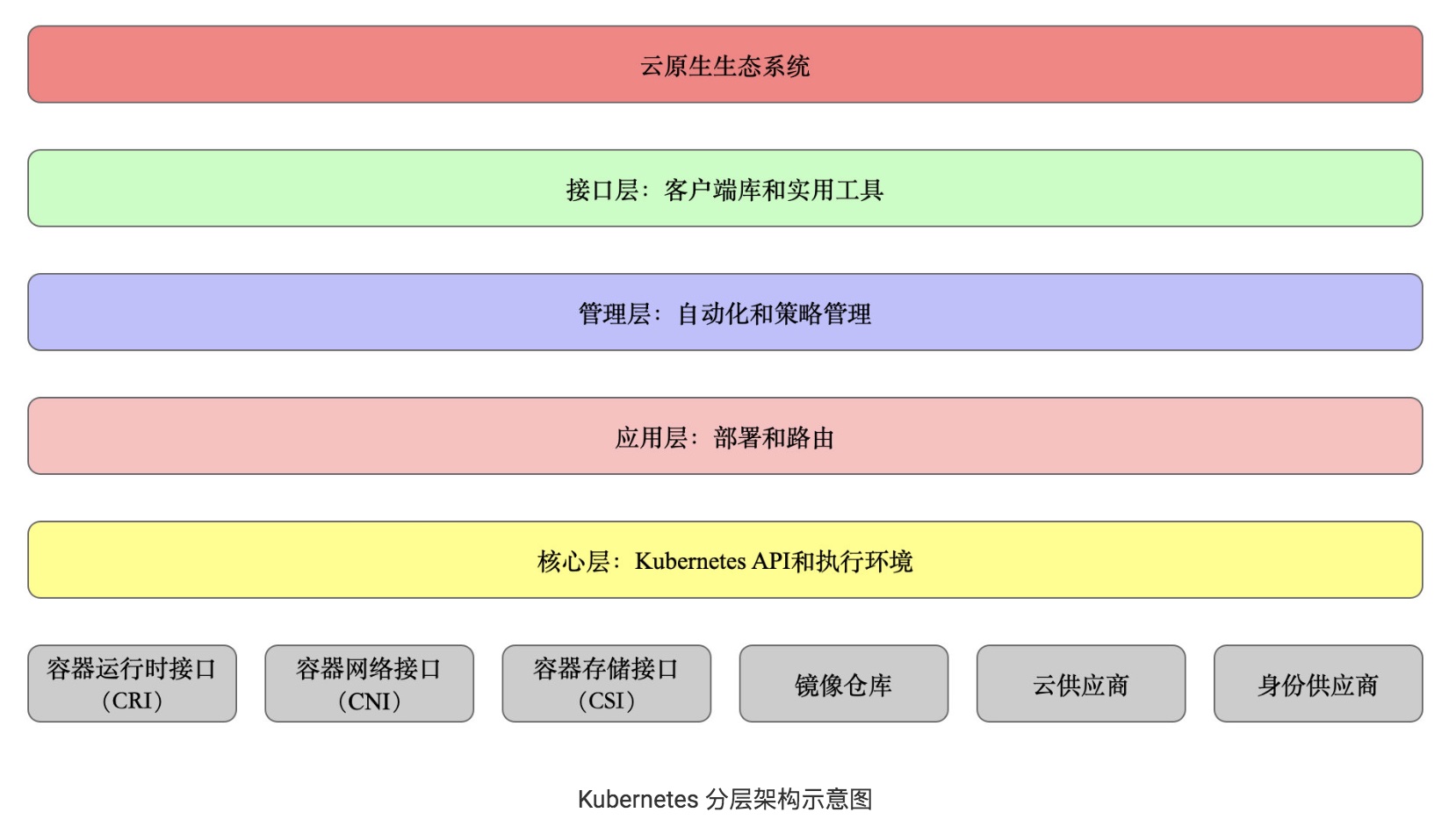
- 核心层:Kubernetes 最核心的功能,对外提供 API 构建高层的应用,对内提供插件式应用执行环境
- 应用层:部署(无状态应用、有状态应用、批处理任务、集群应用等)和路由(服务发现、DNS 解析等)
- 管理层:系统度量(如基础设施、容器和网络的度量),自动化(如自动扩展、动态 Provision 等)以及策略管理(RBAC、Quota、PSP、NetworkPolicy 等)
- 接口层:kubectl 命令行工具、客户端 SDK 以及集群联邦
- 生态系统:在接口层之上的庞大容器集群管理调度的生态系统,可以划分为两个范畴
- Kubernetes 外部:日志、监控、配置管理、CI、CD、Workflow、FaaS、OTS 应用、ChatOps 等
- Kubernetes 内部:CRI、CNI、CVI、镜像仓库、Cloud Provider、集群自身的配置和管理等
核心:一个是 容错性,一个是 易扩展性。容错性实际是保证 Kubernetes 系统稳定性和安全性的基础,易扩展性是保证 Kubernetes 对变更友好,可以快速迭代增加新功能的基础。
API 层设计原则
所有 API 应该是声明式的。
声明式:告知想要什么样的状态,SQL 其实就是一种常见的声明式『编程语言』。
命令式:要达到某个状态需要通过哪些操作,go、C++等都是命令式
API 对象是彼此互补而且可组合的。
API 操作复杂度与对象数量成正比
API 对象状态不能依赖于网络连接状态。
尽量避免让操作机制依赖于全局状态
控制机制设计原则
- 控制逻辑应该只依赖于当前状态
- 假设任何错误的可能,并做容错处理。
- 尽量避免复杂状态机,控制逻辑不要依赖无法监控的内部状态。
- 每个模块都可以在出错后自动恢复。
- 每个模块都可以在必要时优雅地降级服务。
开放接口
**容器运行时接口-****CRI**
容器运行时接口(Container Runtime Interface、CRI)是 Kubernetes 在 1.5 中引入的新接口,Kubelet 可以通过这个新接口使用各种各样的容器运行时。
- RuntimeService 容器和 Sandbox 运行时管理
- ImageService 提供镜像仓库拉取、查看、移除接口
容器网络接口-CNI
现阶段比较流行的插件:Flannel、Calico、Weave
- 由一组用于配置 Linux 容器的网络接口的规范和库组成,同时还包含了一些插件。实现添加网络、删除网络、添加网络列表、删除网络列表
- CNI 插件必须实现一个可执行文件,文件可以被容器管理系统调用(k8s)
- IPAM插件: IP 地址分配
- dhcp 守护进程代表容器发出 dhcp 请求
- Host-local 维护分配本地的 IP 数据库
- Main插件
- bridge 创建网桥,添加主机和容器到该网桥
- Ipvlan 在容器中添加 ipvlan 接口
- loopback 创建回环接口
- Macvlan 创建新的 MAC 地址,将所有流量转发到容器
- ptp 创建 veth 对
- vlan 分配一个 vlan 设备
- IPAM插件: IP 地址分配
容器存储接口-CSI
- CSI 卷插件,用于 Pod 与在同一节点上运行的外部 CSI 卷驱动程序交互。部署 CSI 兼容卷驱动后,用户可以使用
csi作为卷类型来挂载驱动提供的存储。 - CSI 持久化卷支持是在 Kubernetes v1.9 中引入的,作为一个 alpha 特性
Kubernetes的局限性
集群最大支持 5000 个节点
部分场景不支持
Kubernetes 架构和组件
采用分层 CS 架构、客户端通过 RESTful 接口或者直接使用 kubectl 与 Kubernetes 集群进行通信。从架构图上,看出集群分为两大部分。
- 控制平面
- 工作节点
控制平面的组件
作为管理集群状态的 Master 节点,它主要负责接收客户端的请求,安排容器的执行并且运行控制循环,将集群的状态向目标状态进行迁移
ETCD
ETCD 分布式持久化存储,保存集群所有的网络配置和对象的状态信息.Etcd 使用的是 raft 一致性算法来实现的,是一款分布式的一致性 KV 存储,主要用于共享配置和服务发现。【Raft 动画演示】【ETCD 架构解析】
- 多个节点之间数据强一致
- 提供 key 监听机制
- 提供 key 过期和续约机制
- 提供原子的 CAS(Compare-And_Swap),CAD(Compare-And-Delete)。
API 服务/kube-apiserver
apiserver 提供 HTTP Rest 接口,操作资源的唯一入口,提供认证、授权、访问控制、api 注册和发现等机制.
- 每个 API 对象都有 3 大类属性:
- 元数据 metadata:namespace,name 和 uid 和各种各样的 label
- 规范 spec 描述了用户期望 Kubernetes 集群中的分布式系统达到的理想状态
- 状态 status。
调度器/kube-scheduler
scheduler 负责资源的调度,按照预定的调度策略将 Pod 调度到相应的机器上,负责将 pod 分配节点,由 kubelet 来启动容器
直接设置 NodeName。存在 NodeName 未知,资源不足等情况,适用于测试
Node-selector 是基于标签的 pod-to-node。例如:将 ES 调度到 SSD 的节点上
节点(affinity)亲合度调度,节点亲和力(Node Affinity)是在 Pod 上定义的一组约束,用于确定哪些节点适合进行调度,即使用亲和性规则为 Pod 的节点分配定义硬性要求和软性要求。
在 yaml 文件中制定nodeAffinity的关联规则
- requiredDuringSchedulingIgnoredDuringExecution
- requiredDuringSchedulingRequiredDuringExecution
- preferredDuringSchedulingIgnoredDuringExecution
- preferredDuringSchedulingRequiredDuringExecution
required(必须) preferred(首选),IgnoredDuringExecution,Scheduler 在第一次分配后不会检查其有效性。但如果使用 RequiredDuringExecution 指定了规则,Scheduler 会通过将容器移至合适的节点来确保规则的有效性。
污点-Taint,定义 Pod 排斥 Node 的规则
1 | # podspec 具有匹配的 toleration才会讲pod分配在node1上 |
基于 API 的自定义调度策略
调度的瓶颈
- 资源请求(Request)和限制(Limit):“Noisy Neighbor”
- 系统进程资源不足
- 抢占或调度 Pod
调度流程与扩展
调度 Pod 包括两个阶段:调度周期(scheduling cycle)和绑定周期(binding cycle)。
工作流中的以下几点对插件扩展开放:
- QueueSort:对队列中的 Pod 进行排序
- PreFilter:检查预处理 Pod 的相关信息以安排调度周期
- Filter:过滤不适合该 Pod 的节点
- PostFilter:如果找不到可用于 Pod 的可行节点,调用该插件
- PreScore:运行 PreScore 任务以生成一个可共享状态供 Score 插件使用
- Score:通过调用每个 Score 插件对过滤的节点进行排名
- NormalizeScore:合并分数并计算节点的最终排名
- Reserve:在绑定周期之前选择保留的节点
- Permit:批准或拒绝调度周期结果
- PreBind:执行任何先决条件工作,例如配置网络卷
- Bind:将 Pod 分配给 Kubernetes API 中的节点
- PostBind:通知绑定周期的结果
性能瓶颈
当集群节点众多,可以通过percentageOfNodesToScore 将限制节点的数量来计算自己的分数。默认情况下,Kubernetes 在 100 节点集群的 50% 和 5000 节点集群的 10% 之间设置线性阈值。默认最小值为 5%
控制器管理器
controller manager 负责维护集群的状态,比如故障检测、自动扩展、滚动更新等
控制器全集
attachdetach、bootstrapsigner、cloud-node-lifecycle、clusterrole-aggregation、cronjob、csrapproving、csrcleaner、csrsigning、daemonset、deployment、disruption、endpoint、endpointslice、endpointslicemirroring、ephemeral-volume、garbagecollector、horizontalpodautoscaling、job、namespace、nodeipam、nodelifecycle、persistentvolume-binder、persistentvolume-expander、podgc、pv-protection、pvc-protection、replicaset、replicationcontroller、resourcequota、root-ca-cert-publisher、route、service、serviceaccount、serviceaccount-token、statefulset、tokencleaner、ttl、ttl-after-finished
- Node Controller:负责在节点出现故障时进行通知和响应
- job Controller:监测代表一次性任务的 Job 对象,然后创建 Pods 来运行这些任务直至完成
- Endpoints Controller:填充端点分片(EndpointSlice)对象(以提供 Service 和 Pod 之间的链接)。
- Endpoints 表示一个 service 对应的所有 Pod 副本的访问地址
- ServiceAccount controller:为新的命名空间创建默认的服务账号(ServiceAccount)
Node 节点上的组件
Kubelet–Node 的 agent,负责维护容器的生命周期,同时负责 Volume(CSI)和网络(CNI)的管理- Kubelet 服务代理(
Kube-proxy)–负责 Service 提供 cluster 内部的服务发现和负载均衡 - 容器运行时(Docker、rkt 或者其他)–Container runtime 负责镜像管理以及 Pod 和容器的真正运行(CRI)
附加组件
K8S DNS 服务器 –
CoreDNS负责整个集群内的 Pod 提供 DNS 服务微服务的服务发现与 CoreDNS 的服务发现区别
仪表盘(可选)–Dashboard 提供 GUI
Ingress控制器 –Ingress Controller 为服务提供外网流量入口- 进入 Kubernetes pod 的流量称为 Ingress,而从 pod 到集群外的出站流量称为 egress
- 一般使用默认的开箱即用的 Nginx 入口控制器
容器集群监控
Metrics server为 K8S 资源指标获取工具,;Prometheus提供资源监控
CNI 容器网络接口插件–
Calico,Finnel如果没有实施网络策略的需求,那么就直接用 flannel,开箱即用;否则就用 calico 了,但要注意如果网络使用了巨型帧,那么注意 calico 配置里面的默认值是 1440,需要根据实际情况进行修改才能达到最佳性能)
工作流程
TODO
- K8S API
- 日志采集系统实践
- 服务网格
- Istio